3장은 데이터를 저장하는 방법과 데이터를 요청했을 때 다시 찾을 수 있는 방법을 설명한다.
가장 간단한 데이터베이스 구조
bash 함수 2개를 만들어 구현한 key-value 저장소.
#!/bin/bash
db_set(){
echo "$1, $2" >> database
}
db_get(){
grep "^$1, " database | sed -e "s/^$1,//" | tail -n 1
}“db_set {key} {value}” 호출 시, key와 value가 어느 것이든 저장할 수 있다. (value는 JSON도 가능)
“db_get {key}” 호출 시, 해당 key의 가장 최근 value를 찾아 반환해줍니다.
로그
로그는 뒤쪽에 추가만 가능한 추가 전용(append-only) 데이터 파일이다.
db_set함수는 로그를 사용해, 파일 마지막에 데이터를 추가만 해주면 되기 때문에 성능이 좋다. O(1)
db_get함수는 데이터베이스에 많은 레코드가 있으면 성능이 매우 좋지 않다. 매번 키를 찾을 때마다 전체 데이터베이스 파일을 처음부터 끝까지 스캔해야 한다. O(n)
⇒ 데이터베이스에서 특정 키의 값을 효율적으로 찾기 위해서는 다른 데이터 구조가 필요한데, 바로 색인이다.
색인
색인은 기본 데이터(primary data)에서 파생된 추가적인 구조다.
색인의 장점
- 데이터베이스의 내용에는 영향을 미치지 않지만, 원하는 데이터의 위치를 찾는 데 도움을 줘 질의 성능에 긍정적인 영향을 준다.
색인의 단점
- 추가적인 구조(ex.색인)의 유지보수는 쓰기 과정에서 오버헤드가 발생한다. (데이터가 추가될 때마다 색인 데이터에도 그 변경사항을 반영해주어야 하기 때문이다.)
= 색인을 사용할수록 read는 빠르고 write는 오래 걸린다.
색인의 트레이드 오프를 잘 고려하기
색인을 잘 선택했다면 읽기 질의 속도가 향상되지만, 모든 색인은 쓰기 속도를 떨어뜨린다. 데이터베이스 관리자나 애플리케이션 개발자는 쓰기 오버헤드를 발생시키지 않으면서 읽기에는 효율적인, 색인을 수동으로 잘~ 선택해야 한다.
해시 색인
먼저 키-값 데이터를 색인해보자. (보통 해시 맵으로 구현한다.)
가장 간단한 색인 전략은 키를 데이터 파일의 바이트 오프셋에 매핑해 인메모리 해시 맵을 유지하는 전략이다. (인메모리 해시맵에서 키는 텍스트 데이터가 되고, 값은 그 텍스트가 파일에 위치한 바이트 오프셋이 된다.)

이런 방식을 사용하는 저장소 엔진은 해시 맵을 전부 메모리에 유지하기 때문에 고성능 읽기, 쓰기를 보장한다. 덕분에 각 키의 값이 자주 갱신되는 상황에 매우 적합하다. (쓰기가 아주 많지만 고유 키는 많지 않아 모든 키를 메모리에 보관할 수 있기 때문이다. ex. 키는 고양이 동영상의 URL, 값은 비디오가 재생된 횟수인 경우)
하지만 파일에 항상 추가만 한다면 결국 디스크 공간이 부족해진다. 이 상황은 특정 크기의 세그먼트로 로그를 나누는 방식이 좋은 해결책이다. 특정 크기에 도달하면 세그먼트 파일을 닫고 새로운 세그먼트 파일에 쓰기 작업을 수행한다. 그리고 컴팩션을 통해 로그에서 중복된 키를 버리고 각 키의 최신 값만 유지한다.
컴팩션?? 아래 펼치기! ※ 과정도 함께 있어요~
컴팩션
로그에서 중복된 키를 버리고 각 키의 최신 값만 유지한다.
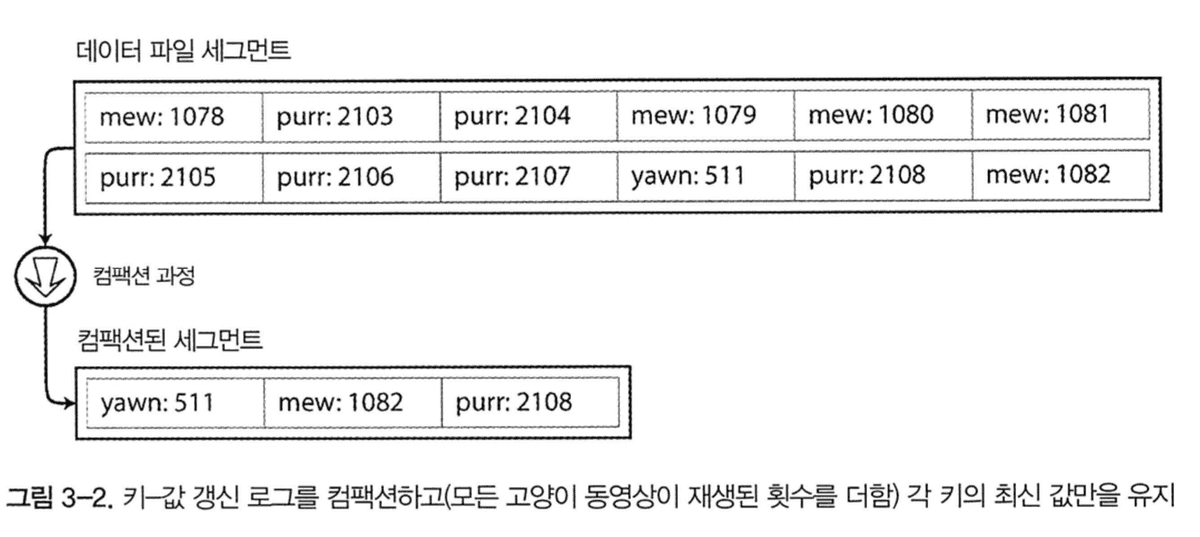
컴팩션과 세그먼트 병합해 세그먼트 수 적게 유지하는 과정
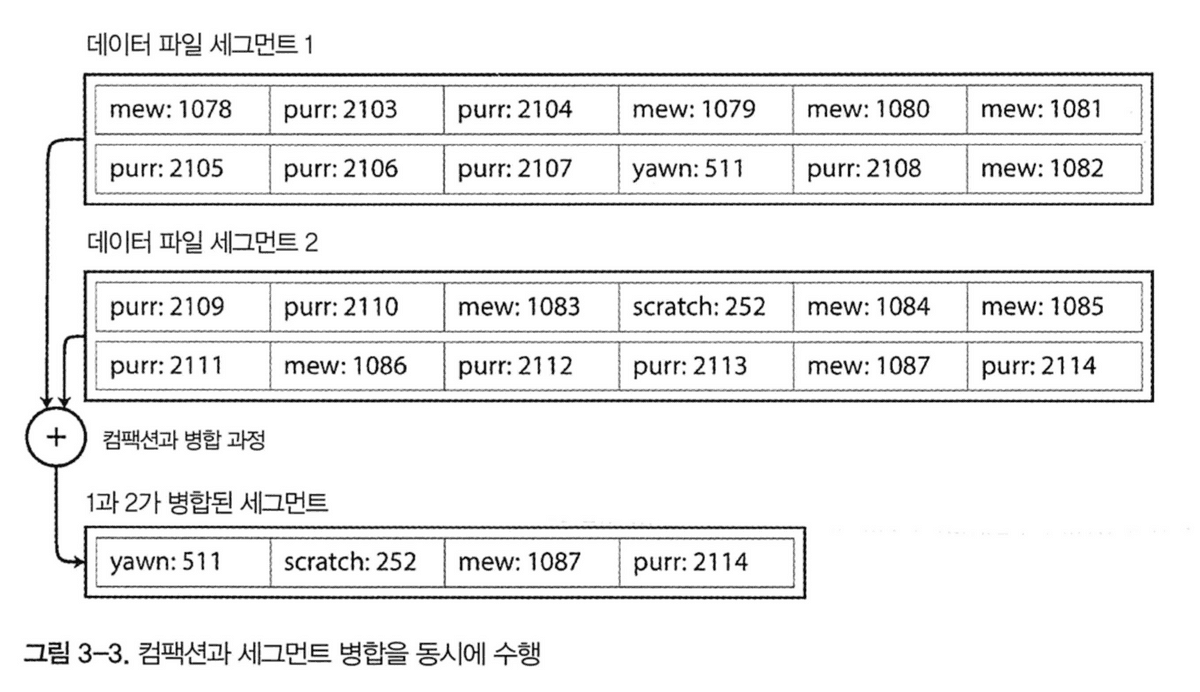
- 세그먼트가 특정 크기 도달 시, 병합을 위한 새 세그먼트 파일 생성
- 이전 세그먼트들 컴팩션과 병합 수행(백그라운드에서 수행)
- 컴팩션 수행 중에는 이전 세그먼트에서 읽기, 쓰기 작업 수행
- 병합이 끝난 후, 새 세그먼트로 전환
- 기존 세그먼트 파일 삭제
- 키의 값을 찾을 땐, 최신의 세그먼트 해시 맵부터 확인
해시 색인 장점
- 순차적인 쓰기 작업이기 때문에 무작위 쓰기보다 훨씬 빠르다.
- 세그먼트 파일이 불변이거나 추가 전용이면 고장 복구가 간단하다.
- 오래된 세그먼트 병합은 시간에 따라 발생하는 데이터 파일의 조각화 문제를 피할 수 있다.
해시 색인 단점
- 메모리 상에 해시 테이블을 저장하는 데는 용량의 한계가 있다. 디스크에 저장 시 좋은 성능을 기대할 수 없다.
- 범위 질의에 대해 효율적이지 않다. (ex. 0000~9999 키를 스캔시, 모든 개별 키를 조회해야 한다.)
'데이터 중심 애플리케이션 설계' 카테고리의 다른 글
| [데이터 중심 애플리케이션 설계] 3장 3. OLTP와 OLAP, 데이터 웨어하우스, 정리 (0) | 2023.03.24 |
|---|---|
| [데이터 중심 애플리케이션 설계] 3장 2. LSM 트리와 B 트리 (0) | 2023.03.24 |

